将对象恰当地放置在场景中对计算机比对人要困难得多。它不仅需要为所述对象确定适当的位置,而且还需要尝试预测目标位置上的对象的外观——规模、遮挡、姿势、形状等等。但有人工智能(AI)的帮助,情况就不同了。首尔国立大学、加州大学默塞德分校和谷歌 AI 的研究人员新研发的一个系统,可学习插入对象到一个“语义连贯”的形象中。
研究人员在向 NeurIPS 2018 会议提交的一篇论文(《对象实例的语境感知合成和放置》)中,描述了这个系统。
“在符合场景语义的图像中插入对象是一项具有挑战性也很有趣味性的任务。这项任务与许多实际应用密切相关,包括图像合成、AR 和 VR 内容编辑以及领域随机化,”研究人员在论文中写道。“这样一个对象插入模型有助于增强众多图像编辑和场景解析应用程序。”
根据描述,该系统包括两个模块,一个模块确定插入的对象应该在哪里,另一个模块确定插入的对象应该是什么样子,这两个模块利用 GAN,或者由产生样本的生成器和试图分解的鉴别器组成的两部分神经网络,在生成的样本和真实世界样本之间进行比较。因为系统同时对插入图像的分布进行建模,所以它使得两个模块能够相互通信并彼此优化。
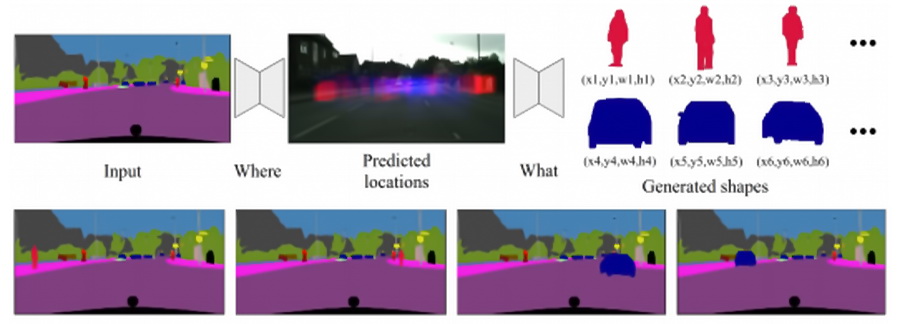
“这项工作的主要技术创新之处在于构造一个端到端的可训练神经网络,它能够从新物体的联合分布中取样出可能的位置和形状。”论文写道,“合成的对象实例既可以作为基于 GAN 的方法的输入,也可以从现有数据集中检索最近的片段,从而生成新的图像。”
根据论文所作的解释,生成器预测“合理的”位置,以生成具有“语义一致的”比例、姿势和形状的对象掩码——具体来说就是对象如何在场景中分布,以及如何自然插入对象,使其看起来是场景的一部分。随着时间的推移,在训练过程中,人工智能系统会根据场景的不同学习不同的对象类别分布——例如,在城市街道的图像中,人们往往在人行道上,而汽车通常在路上。
在测试中,研究人员通过插入真实形状的物体,使模型表现优于基线。当将图像识别器 YOLOv3 应用于人工智能生成的图像时,能够以 0.79 的召回率检测合成目标。在亚马逊土耳其机器人公司(Mechanical Turk)对员工进行的一项调查中,43%的人认为人工智能生成的物体是真实的。
“这表明我们的方法能够执行对象合成和插入任务。”研究人员写道。“由于我们的方法是在什么位置和什么对象上共同建模的,它可以用于解决其他计算机视觉问题。未来有趣的工作之一将是处理物体之间的遮挡。”【数字叙事 黎雾】

