GPT-3 等大型语言模型显示出了令人信服的生成能力:可以撰写散文、诗歌,编写 HTML 代码和 Excel 电子表格,且结果有时甚至与人类文本无法区分。这些 AI 模型通常根据学习的内容对人类提供的输入文本进行补充,但输出难以控制,生成文本的验证也很困难,且无法解释为什么会产生某些陈述。更重要的问题是,它们与人类作者的合作只能在有限的范围内进行。
因此,OpenAI、谷歌、Meta 等公司都在努力使模型变得更为可靠。最近,Meta 推出的 PEER,展示了人类和 AI 之间的协作可能是什么样子。PEER 是使用维基百科的编辑历史进行训练的,维基百科广泛的文本编辑和相关评论数据集能为文本的变化提供样本和解释,因此,通过该模型可以对文本进行各种更改并对其进行解释。
据 Meta 研究人员介绍,PEER 的文本生成反映了人类的写作过程。对于给定的文本,人类或 AI 模型可以创建计划,例如通过输入文本。这样的计划可以包括更正文本中包含的不正确信息、添加参考或更改格式。然后,模型可以解释这些变化,例如参考来源。为此,PEER 在进一步处理之前,会为每个输入文本提供可能相关的背景信息。
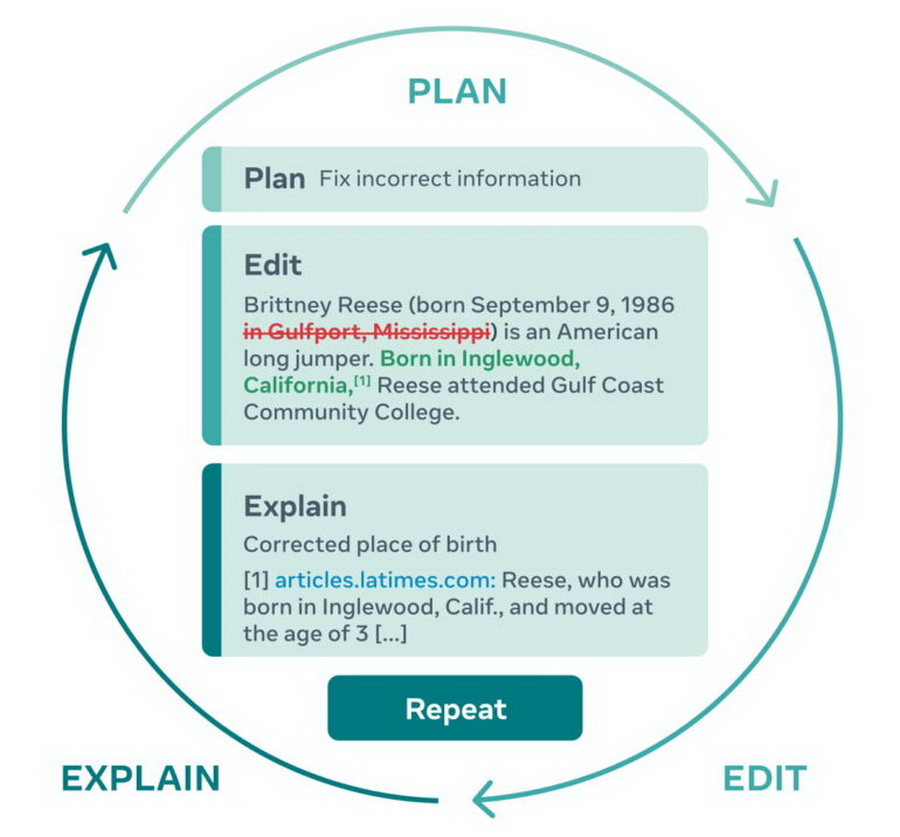
然后,PEER 可以根据人类作者的需要多次重复此过程。这种迭代方法将编写一致且真实的文本的复杂任务分解为几个更简单的子任务,人们也可以随时干预和控制这些子任务。
为了确保 PEER 在类似于维基百科的文本之外也有用,PEER 的变体还学习了从完全编辑的文本和相关文档中重建原始的、未编辑的文本。使用这种方法,Meta 创建了一个在维基百科域之外也会有用的 AI 模型。

与 GPT-3 或 OPT 等其他大型语言模型相比,30 亿参数的 PEER 作为写作助手的性能更好。不过,根据 Meta 的说法,PEER 作为一种协作语言模型的能力尚未得到全面的发掘和验证。未来,该团队希望从众多 AI 与人类的交互中收集完整的会话,以进一步提升 PEER。
Meta 研究团队希望首先解决 AI 语言模型的进一步约束问题。例如,PEER 必须能够访问可独立查找相关文档的检索引擎。此外,研究人员还必须开发评估由人类和 AI 模型共同编写的文本的方法,并提高 PEER 的效率,以便能够处理整个文档。【数字叙事 Lighting】

