谷歌最新的图像 AI 模型 Parti(Pathways Autoregressive Text-to-Image)允许从更广泛、详细的描述中生成图像,这使其比谷歌不久前推出的 AI 模型 Imagen 能更精确地控制结果。
Imagen 的图像生成具有与 Open Ai 的DALL-E 2 相似的架构,但输入依据的是大型 AI 语言模型——由于具有更高的语言理解能力,因此可以从文本描述获得更好的图像生成结果。新的 AI 模型 Parti 尝试使用一种更接近大型语言模型功能的替代架构(自回归),这些语言模型能根据之前的单词和句子或段落的上下文预测合适的新词。Parti 将这一原则应用于图像,并取得了成功。
Parti 表明,与大型语言模型一样,图像 AI 通过更全面的训练和更多的参数获得了明显更好的结果。它还可以将长而复杂的文本输入准确地翻译成图像,这表明它可以更好地理解语言和主题之间的关系。

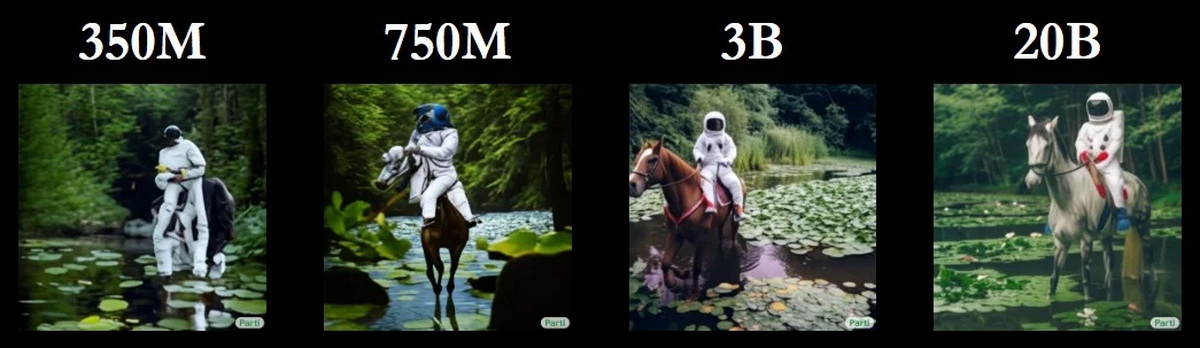

Parti 生成的图像分辨率为 256 x 256 像素,然后可以放大到 1024 x 1024 像素。上图显示了四种经过不同级别训练的 Parti 模型在相同命令提示下生成图像的质量差异。具有 200 亿参数的最大模型生成了与长文本输入匹配的无错误图像。最大版本的 Parti 模型甚至可以拼写单词,而 DALL-E 2 只能生成图像。
“20B 模型特别适合于需要世界知识、特定视角或符号书写和表示的抽象任务。”谷歌的研究团队写道。
另外,Parti 还可以生成超越培训材料及其主题的出色的图像。研究人员认为,这意味着图像 AI 能够准确地再现世界知识,以精细的细节和交互组合产生许多主角和对象,并遵循特定的图像格式和风格。【数字叙事 Lighting 编译】

