随着 AI 模型的发展,图像 AI 的表现越来越出色。DALL-E 2、Midjourney和Imagen等多模态 AI 模型均允许通过文本输入来生成图像,并且经常能产生富有创造性的结果。但是,用户对这些系统的控制十分有限,基本是输入文本,然后等待结果,而得到的图像常常并不符合我们的想法。
Meta 最近展示的多模态 AI 模型 Make-A-Scene 则通过草图加文本的输入赋予了用户更多的控制权,从而能生成更有针对性的图像。方法是:先输入定义了基本场景布局的草图,然后通过文本输入来对框架进行填充。
当然,Make-A-Scene 也可以通过输入文本来创建自己的布局——但这意味着用户放弃了部分控制权。
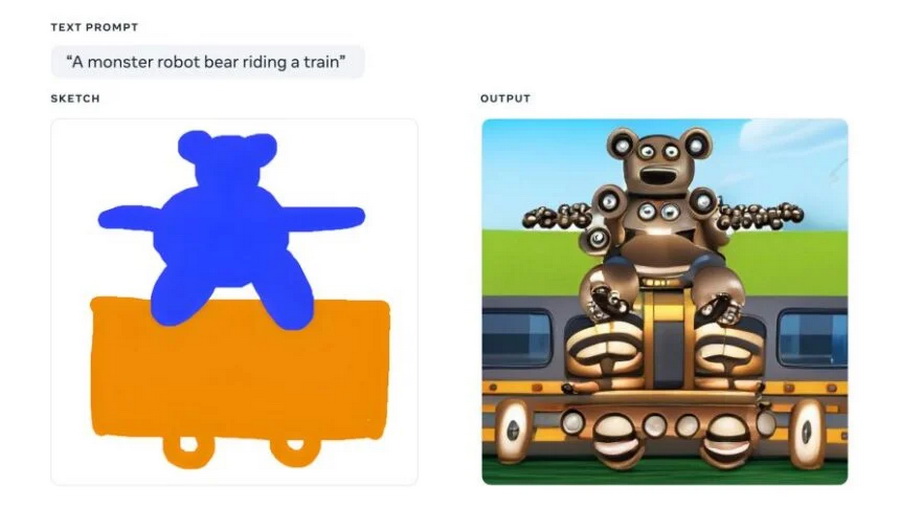
据 Meta 介绍,一些艺术家已经获得了 Make-A-Scene 的试用权限。不过,该模型暂时不会发布:对于 Meta,Make-A-Scene 是 AI 创造力的实验,重点是用户控制。
Meta 表示,为了利用人工智能的潜力来促进创造性表达,人类需要能够塑造和控制系统生成的内容。为此,相应的系统必须直观且易于使用——包括语言、文本、草图、手势或眼球运动。
一直以来,Meta 希望借助人工智能开发一种新型的数字创意工具,使许多人能够在 2D、XR 和虚拟世界中创建富有表现力的信息。【数字叙事 Lighting】

